Classification
Displaying a name by itself isn't very useful, so I'm exploring adding a classification to the ant demo. The question is which one? As a trial I've decided to use ITIS, based on the October 12, 2005 dump used by uBio (you can see it here). There are some 15,000 ant taxa in ITIS.

The plan is to retrieve the classification by spidering the uBio site, starting with the RDF for Formicidae in the ITIS classification (urn:lsid:ubio.org:classificationbank:5095531). By following the <ubio:hasChild> tags, we can traverse the complete tree.
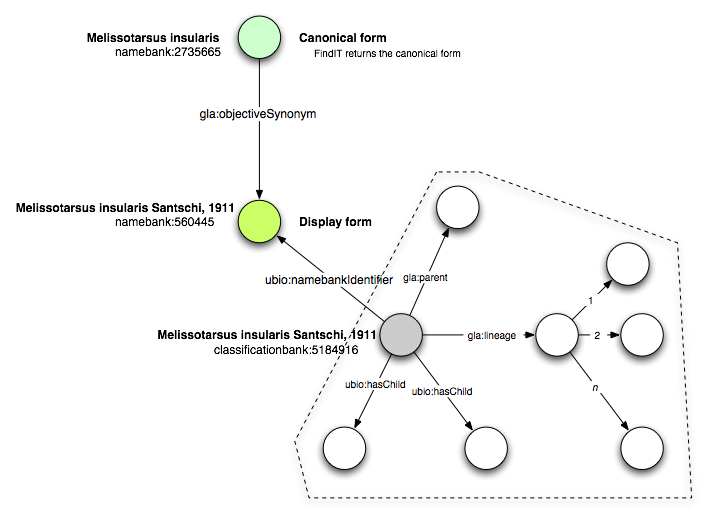
One issue is getting my head around uBio's name structure. I use their FindIT SOAP service to get LSIDs for names from NameBank. FindIT returns canonical name ids, but ClassificationBank uses different LSIDs for the names (the "display name"). To give a concrete example, using FindIT to search on "Melissotarsus insularis" yields the LSID urn:lsid:ubio.org:namebank:2735665, whereas in the ITIS classification, the ClassificationBank record (urn:lsid:ubio.org:classificationbank:5184916) links to urn:lsid:ubio.org:namebank:560445.


The plan is to retrieve the classification by spidering the uBio site, starting with the RDF for Formicidae in the ITIS classification (urn:lsid:ubio.org:classificationbank:5095531). By following the <ubio:hasChild> tags, we can traverse the complete tree.
One issue is getting my head around uBio's name structure. I use their FindIT SOAP service to get LSIDs for names from NameBank. FindIT returns canonical name ids, but ClassificationBank uses different LSIDs for the names (the "display name"). To give a concrete example, using FindIT to search on "Melissotarsus insularis" yields the LSID urn:lsid:ubio.org:namebank:2735665, whereas in the ITIS classification, the ClassificationBank record (urn:lsid:ubio.org:classificationbank:5184916) links to urn:lsid:ubio.org:namebank:560445.
posted by Roderic Page at
Friday, June 30, 2006
![]()

6 Comments:
rod
how to you resolve then the issue about LSIDs? Here we have already two, and we are creating a third (with HNS). Furthermore, how to you deal with the problem that the various sources aren't the same: ITIS gets from time to time an upgrade from HNS, and Ubio ought to their data from HNS, but keep adding most likely other names to discover, but they can not resolve the relationship between new names they discover and existing (concepts).
So aren't we running into a plethora of LSIDs, and thus pushing the problem of authority files just one step further instead of resolving it?
Donat
By Donat Agosti, at 2:00 pm
Donat Agosti, at 2:00 pm
Not sure what you mean by authority files. As I see it, there are "names" and, it pains me to use the word, "concepts". uBio has more names than anybody, plus tools for their extraction. They also serve LSIDs, so for me they are the only game in town.
What they don't do is give you the currenly accepted name, nor detailed synonymies. This is what I'd hope to get from the Hymenoptera Name Server. Having multiple LSIDs isn't a huge problem, providing links between them are preserved (i.e., if we know that a name in ITIS is the same as one in HN).
The reality is that any digital object of interest is likely to have more than one identifier. I also think we should avoid thinking of "authority files". I'm not trying to make any claims that this or that name is authoritative. At this stage I just want to link the data.
Lastly, I want this stuff to be as generic as possible, so it can be applied to any group of organisms. That means uBio as the default source of names, and then other sources for more detail, synonymy, etc.
By Roderic Page, at 1:25 am
Roderic Page, at 1:25 am
As an aside, I suspect that "taxonomic concepts" are really not data but inferences. If we had all the ant taxonomic literature digitised, complete with synonym lists, and we have some basic inference rules derived form the rules of nomenclature, then can't we simply compute the current name? This may be wishful thinking, but I think what matters are the names, and relationships between them.
Indeed, if we have that, then we may not need to worry too much about accepted names. We make a choice of name based on whatever classification we prefer. What I suspect will happen is that, once people realise that we could compute what a name means in two different classifications, then the issue will fade.
By Roderic Page, at 1:33 am
Roderic Page, at 1:33 am
This comment has been removed by a blog administrator.
By Roderic Page, at 1:34 am
Roderic Page, at 1:34 am
Since it is now so obvious about the different ADA expert administrations and use cases, you might be asking for what reason to put resources into them in any case. Check the accompanying convincing reasons: ADA is, most importantly, a lawful prerequisite out. Recruiting an ADA expert implies that your association thinks often about its moral obligations and adds to inclusivity. It additionally assists you with keeping away from potential legitimate results like punishments and claims>> ada compliance officer
By JacobHarman, at 10:51 pm
JacobHarman, at 10:51 pm
Very thoughtful bloog
By a part of me, at 4:59 pm
a part of me, at 4:59 pm
Post a Comment
<< Home