Adding triples using EditGrid

Vince Smith has constantly been telling me that for many biologists, "database" means an Excel spreadsheet, and that a big problem is simply getting data into a form that can be used online. Bearing that in mind, and also mindful of how much data is kicking around that isn't in "real" databases, I've been playing with EditGrid as a tool for adding triples to a triple store. I've commented on EditGrid elsewhere in the context of collaborative data matrices.
So, here's the situation. In my triple store I have information on ant specimen INBIOCRI001284215, obtained from AntWeb. Now, AntWeb has no pictures of this specimen. However, John Longino's pages on Acromyrmex coronatus include pictures of this specimen. How do I get that information into my triple store, without writing RDF?
One approach is to create a spreadsheet with three columns (subject, predicate, object), and create the triples, one per row. Now, I could just do this on my computer using, say, Excel, but that's not nearly cool enough, so I'll use EditGrid. But seriously, I'm going to use EditGrid because:
- You can see it, whereas you can't see a file on my computer
- You and I could collaborate on editing the data in EditGrid
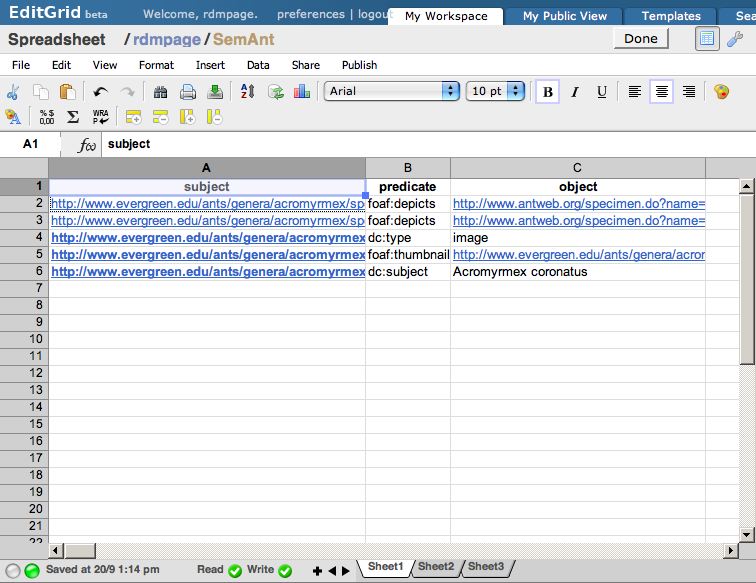
The spreadsheet contains triples, such as these:
| subject | predicate | object |
| http://www.evergreen.edu/ ... /INBIOCRI001284215_face_orig.jpg | foaf:depicts | http://www.antweb.org/ ... inbiocri001284215 |
In this case the subject and the object are represented by URIs (here they are URLs, but they could also be LSIDs or DOIs). You can see the complete spreadsheet here. The triples link the picture to the specimen, tell us that http://www.evergreen.edu/ants/genera/acromyrmex/species/coronatus/INBIOCRI001284215_face_orig.jpg is a picture (dc:type image), that the picture has a thumbnail, and is of Acromyrmex coronatus. Armed with these triples, I can now find a picture of this ant in my triple store.
Fine so far, but how do we get this into the triple store I hear you ask? EditGrid's permalink feature can export the spreadsheet in a range of formats, including XML. So, what I do is grab the XML, apply a XSL style sheet to convert it to RDF, then import the resulting RDF into the triple store. The key thing is once the data is in the spreadsheet, the rest is trivial. Here's the XSL style sheet. It has limitations, notably the assumption that URIs are URLs.
<?xml version='1.0' encoding='iso-8859-1'?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<xsl:output method="xml" version="1.0" encoding="iso-8859-1" indent="yes"/>
<xsl:template match="workbook">
<rdf:RDF>
<xsl:apply-templates select="//row"/>
</rdf:RDF>
</xsl:template>
<xsl:template match="row">
<xsl:if test="@row != '0'">
<xsl:element name="rdf:Description">
<xsl:attribute name="rdf:about">
<xsl:value-of select="cell[1]/@input"/>
</xsl:attribute>
<xsl:variable name="predicate" select="cell[2]/@input"/>
<xsl:variable name="object" select="cell[3]/@input"/>
<xsl:choose>
<xsl:when test="contains($object, 'http://')">
<xsl:element name="{$predicate}">
<xsl:attribute name="rdf:resource">
<xsl:value-of select="$object"/>
</xsl:attribute>
</xsl:element>
</xsl:when>
<xsl:otherwise>
<xsl:element name="{$predicate}">
<xsl:value-of select="$object"/>
</xsl:element>
</xsl:otherwise>
</xsl:choose>
</xsl:element>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
This particular spreadsheet makes some assumptions of the user, namely that they can figure out what is the subject and what is the object, and are comfortable choosing predicates. However, being collaborative, others could help out by editing the spreadsheet. Furthermore, one could create spreadsheets that aren't quite so complicated, and aren't geared towards the developer. For example, one basic source of information I'd like to capture is geographic location, and there is probably a lot more information available in papers than in georeferenced museum collections. Hence, a spreadsheet like this
| observation | lat | long |
| locality | -34.0 | 156.26 |
could be used to capture locality information, and would require minimal effort to convert into RDF. We'd just have to modify the XSL style sheet shown above.
The key point of all of this is that with minimal effort we can capture information that is not in the triple store, and we can make it eas(ish) for people with data to contribute. Given that EditGrid can import Excel files, somebody interested in sharing their data could do the grunt work in Excel on their own computer, then move everything to EditGrid, which makes it accessible to others.
Simple and open wins...
posted by Roderic Page at
Wednesday, September 20, 2006
![]()

{kind=link}
4 Comments:
Hi, this is David from EditGrid team. You've demonstrated a very interesting use of EditGrid!
I'm not sure whether you've notice it yet - EditGrid has a "My Data Format" feature, which allows you to input your own XSL (you have got it already!) to transform the spreadsheet's XML import to any format of your choice.
After using this feature, you should be able to produce RDF directly through an EditGrid permalink of your choice, e.g.
http://www.editgrid.com/user/rdmpage/SemAnt.rdf
To access to My Data Format, please go to the sheet properties of your spreadsheet -> "My Data Formats" -> "Create New Data Format".
Should you have any questions or difficult using this feature, please visit our forum: http://forum.editgrid.com.
Thanks for using EditGrid.
By Anonymous, at 3:44 pm
Anonymous, at 3:44 pm
That's a cool feature, I'll need to play with that.
The other thing I'm curious about is how to tell whether the spreadsheet has been edited. For example, if I subscribe to a RSS feed I can use conditional HTTP GET to check whether the feed has changed -- if it has I can fetch it, if not I don't need to. Is it possible to do the same for an EditGrid spreadsheet, so that I don't need to grab the whole document every time?
By Roderic Page, at 3:59 pm
Roderic Page, at 3:59 pm
A practical problem is of course the choice of predicates from a vocabulary of millions of potential URIs. In prinicpal, that is universal, but it is relevant if the assumption is that raw tools suffice and are easy. This reminds me a bit of the older DELTA pioneers who simply had remembered the their characters and state numbers (i.e. equivalent of URIs) by heart.
A more general thing that bothers me about using RDF: if I have many such statements without knowing who made them (e.g. someone I know, someone I know can identify this ant, someone I know cannot), perhaps when (I myself as a student years ago or just now), and under which circumstances (including whether from own observation or citing other sources), these data become of doubtful value.
Dealing with this in RDF using reification mechanism seems to be a management problem. I belief treating statements as naturally related (e.g. a chapter in a book, a wiki page) is more natural than treating them as atomic.
Gregor Hagedorn
By Anonymous, at 4:32 pm
Anonymous, at 4:32 pm
Not sure about millions of potential predicate URIs. In practice, most things I'm interested in already have vocabularies (such as Dublin Core, PRISM, FOAF, geo etc.). As I've argued at the TDWG GUID meetings, I think there's actually very little we need to add to these, and I despair at how much the taxonomic community seems determined to reinvent this stuff.
I'm wondering if by predicates you mean things such as attributes of organisms. I think this is something entirely separate, and is best tackled in the context of an ontology of terms for particular organismal groups. Or, perhaps as a problem for informal tagging, which may prove more successful. Efforts at large-scale formal approaches have not been terribly successful in the past.
Regarding who said what, this is an important topic, and in addition to reification there is the the notion of "named graphs" to indicate provenance. This paper by Carroll et al. is a good place to start. For example, I can identify all triples that came from AntWeb using a named graph. I could also identify the triples from a particular EditGrid spread sheet by the URI of that spreadsheet.
By Roderic Page, at 5:13 pm
Roderic Page, at 5:13 pm
Post a Comment
<< Home