Automatically growing an ant bibliography
Earlier on iPhylo I'd mentioned the issue of updating a triple store of ants, or indeed, any data base. As an experiment, I've put together a Perl script that can be used to update a data base in Connotea with recent papers on ants. The script makes of a number of web services, and uBio's RSS feeds. It does the following:
Here's a sketch of the process.
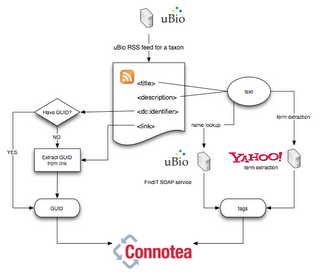
The papers are stored in my semant library. Because it is entirely automated, it could be run regularly (as a cron job, say) to update the library, hence the list of ant papers would grow without any human intervention. At the same, however, users with access to the semant library could manually edit the tags if they feel Yahoo and uBio have missed some relevant terms.
Note also that names recognised by uBio are tagged with LSIDs for the names as well, which means we could resolve those to RDF. In the same way, the Connotea data base itself can serve RDF (here are the ant papers in RDF). Hence, we could easily populate a triple store with metadata about papers and names.
What I like about this script is that it brings together a number of themes.
GUIDs play a key role here. Connotea knows which papers uBio has extracted by using the DOI (or PubMed identifier). Not only does this enable Connotea to know which paper I want, but it uses that identifier to extract metadata about the paper, for example via CrossRef. It also knows whether any other user has already added that paper.
Web services mean that I don't have to reinvent the wheel. If I want to pick out taxonomic names, I use uBio. To extract keywords for tagging, I use Yahoo. To store data, I use Connotea's API.
Tagging makes it easy to add information to a reference.
Social networking through using an open database like Connotea. People can discover other people's libraries through shared papers or shared tags.
RSS pops up at the start and at the end. The whole process starts with a RSS feed (itself an aggregation of numerous journal RSS feeds), and the resulting Connotea data base serves RSS, so others can readily make use of the results.
- Takes an RSS feed for Formicidae from uBio. This feed lists recent papers on ants, as identified using uBio's taxonomic name recognition algorithms.
- Extracts DOIs or PubMed identifiers from the RSS feed. If a DOI isn't found, I see if we can extract one from the <link> tag (typically a URL to the article). uBio does a pretty good job of getting DOIs, but misses some (e.g., for Blackwell and BioOne journals).
- Extracts taxonomic names from the content of the <title> and <description> tags using a SOAP call to uBio's FindIT web service. Ideally, uBio would do this for us, since it has already parsed the journal feed, but for now I do it.
- Uses Yahoo's term extraction web service to extract keywords
- Submit the article GUID (DOI or PubMed id), and the tags to Connotea using the web API.
Here's a sketch of the process.
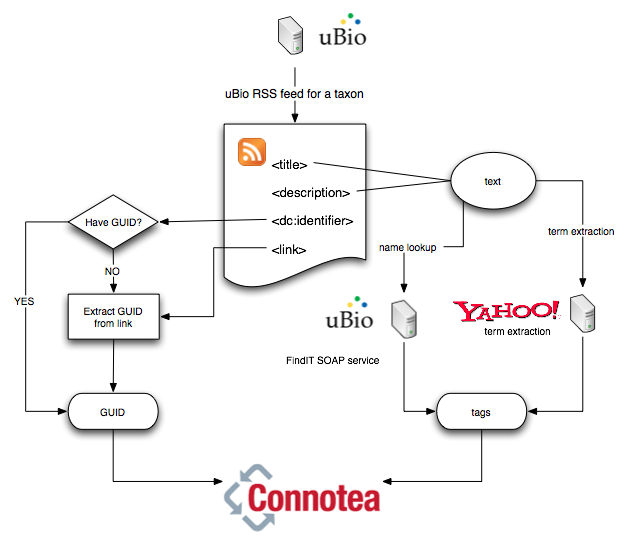
The papers are stored in my semant library. Because it is entirely automated, it could be run regularly (as a cron job, say) to update the library, hence the list of ant papers would grow without any human intervention. At the same, however, users with access to the semant library could manually edit the tags if they feel Yahoo and uBio have missed some relevant terms.
Note also that names recognised by uBio are tagged with LSIDs for the names as well, which means we could resolve those to RDF. In the same way, the Connotea data base itself can serve RDF (here are the ant papers in RDF). Hence, we could easily populate a triple store with metadata about papers and names.
What I like about this script is that it brings together a number of themes.
GUIDs play a key role here. Connotea knows which papers uBio has extracted by using the DOI (or PubMed identifier). Not only does this enable Connotea to know which paper I want, but it uses that identifier to extract metadata about the paper, for example via CrossRef. It also knows whether any other user has already added that paper.
Web services mean that I don't have to reinvent the wheel. If I want to pick out taxonomic names, I use uBio. To extract keywords for tagging, I use Yahoo. To store data, I use Connotea's API.
Tagging makes it easy to add information to a reference.
Social networking through using an open database like Connotea. People can discover other people's libraries through shared papers or shared tags.
RSS pops up at the start and at the end. The whole process starts with a RSS feed (itself an aggregation of numerous journal RSS feeds), and the resulting Connotea data base serves RSS, so others can readily make use of the results.
posted by Roderic Page at
Monday, October 23, 2006
|
63 comments
![]()


